Infrastructure Testing with Sensu and RSpec
The Divide
Despite agile, cross-functional product teams there is often still a clear separation between Engineering (development and testing functions) and Operations. Assuming a Continuous Delivery pipeline, there is strong collaboration between the three areas in local (e.g. Vagrant), test and stage environments. However, when it comes to the production environment, Operations typically have the keys to the castle (complete with moat and drawbridge).
This isn’t necessarily a bad thing - roles and responsibilities are clearly defined for good reason. But it does help reinforce the Engineering-Operations divide of “we build it, you run it”.
Shared Responsibility
A tangible way to help bridge this divide is with a set of behaviour-driven infrastructure tests.
The idea is to run a set of tests at regular intervals across all environments (especially Production) to monitor your application from a behavioural perspective. When tests fail, they raise very specific errors regarding your application. The benefits here are twofold:
- It enables Operations’ to understand the application behaviour.
- It improves Engineering’s understanding of how the environment effects the application.
Over time, this leads to increased collaboration between two teams that tend to be deeply entrenched.
Operations will be exposed to very specific alerts when tests fail which they can feed back to the Engineering team (e.g. service X has gone unhealthy because it depends on service Y which has lost database connectivity). They can also suggest - and contribute - new tests for missed or problem areas.
The Engineering team can understand how their application works at scale in a complex environment (e.g. with load-balancing, caching, multiple instances). This can aid troubleshooting complicated edge-cases such as message queuing, race conditions and cache invalidation which may be difficult to simulate locally.
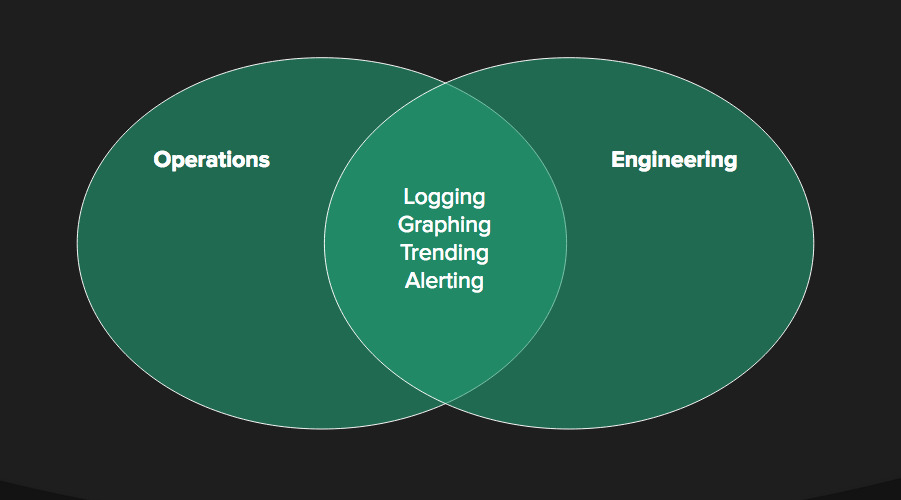
The goals of universal logging, graphing, trending and alerting are strong drivers for both teams, helping to expose, debug and fix issues.
Introducing Sensu
Sensu is an open-source monitoring framework designed with the cloud in mind. Taken straight from the documentation:
Sensu takes the results of “check” scripts run across many systems, and if certain conditions are met; passes their information to one or more “handlers”. Checks are used, for example, to determine if a service like Apache is up or down. Checks can also be used to collect data, such as MySQL query statistics or Rails application metrics. Handlers take actions, using result information, such as sending an email, messaging a chat room, or adding a data point to a graph.
From my experience of using Sensu for the past few months across all ITV’s AWS environments (including Production), I can confirm that it’s a really awesome tool. It’s much more powerful, configurable and easy-to-use than Zabbix or Nagios.
Sensu provides an open-source repository which contains a large number of “checks” and “metrics” which you can use. You can also use any existing Nagios plugins that you might have.
You can fully configure Sensu using Puppet or Chef (we use the former).
It also provides an API which also allows you to configure different dashboards e.g. Uchiwa.
A Working Example
Let’s take a look at how you can run your infrastructure tests and raise alerts for failures.
For this we need:
- some tests to run
- a Sensu server
- a Sensu client
- a Sensu “check” to run our tests
Fortunately, I already wrote an RSpec Sensu check plugin!
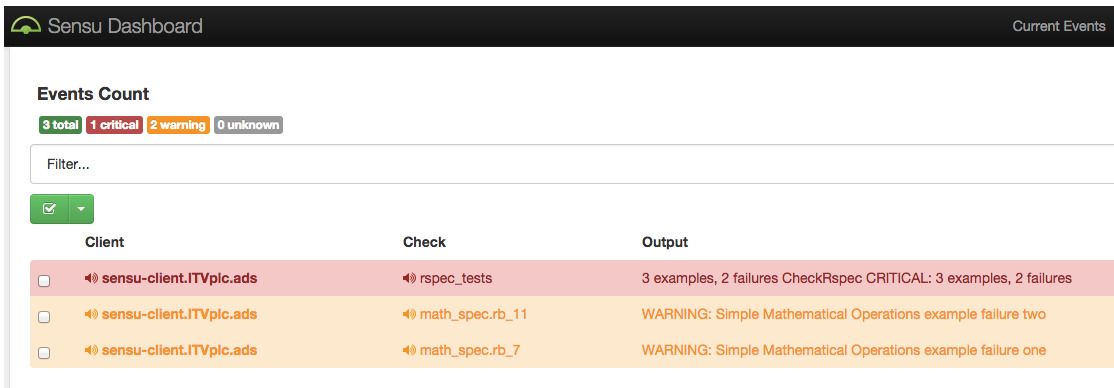
I have a working example that contains all the above where you can see Sensu running some failing RSpec tests and consequently raising alerts.
Once you have the Vagrant VMs up and running you can see the (deprecated) Sensu dashboard with the alerts:
Credits
Thanks to Michael Richardson[3] for originally coming up with a similar idea (Sensu + Serverspec).
Thanks to Graham Taylor[4] for the Sensu Serverspec plugin which I based my Sensu Rspec plugin on.
Thanks to Rob Taylor[5] for replicating the first two images ([1] and [2] respectively).
Comments
comments powered by Disqus